
Imagine trying to write an instruction manual that tells a computer exactly how to spot a dog in a photograph. You might start by programming rules like “look for two floppy ears, a button nose, and fur.” But what happens when the dog is facing away from the camera? What if it’s a hairless breed like a Xoloitzcuintli? Or what if it’s hiding behind a couch, leaving only its tail visible?
If you try to write a rule for every single scenario, your software code will never end. It will get tangled, conflict with itself, and eventually crash. That exact roadblock is why software developers had to completely flip the script on traditional programming. To really grasp how machine learning works, you just have to look at how we learn as humans. You didn’t figure out what a dog was by memorizing a rigid checklist of anatomical rules. You learned by looking at hundreds of dogs over time until your brain automatically recognized the pattern.
Machine learning hands this exact same capability to computers. Instead of writing strict, fragile instructions, engineers feed a computer tons of examples and let it figure out the underlying patterns on its own. It runs almost everything we interact with online today. It’s behind the movies Netflix pushes to your dashboard, the system that flags credit card fraud before you even notice, and the software your favorite B2B SaaS platform uses to predict customer churn.
The Fundamental Shift: Rules vs. Data
For decades, traditional software development followed a predictable path. A human programmer wrote explicit instructions, loaded in some data, and the computer spit out the answers. If the situation shifted even slightly, a human developer had to dive back into the source code and rewrite the logic manually.
Machine learning completely reverses this formula. Instead of giving the computer the rules up front, you give it the data and the final answers. The computer’s job is to figure out the rules that connect them.
Think about predicting whether a customer will renew their software subscription. A traditional programmer would try to write a complex mathematical formula factoring in log-in frequencies, open support tickets, and account age. A machine learning system takes a completely different path. It looks at a massive spreadsheet containing data on thousands of past customers, noting their specific behaviors alongside the final outcome—whether they renewed or canceled. By analyzing that historical data, the system builds its own internal logic to predict what your current customers will do next month.
When developers talk about an AI “model,” they simply mean the final set of rules the computer built for itself during this process.
|
Feature |
Traditional Programming |
Machine Learning |
|
Input |
Rules and Data |
Answers and Data |
|
Output |
Answers |
Rules (The Model) |
|
Approach |
Explicitly coded step-by-step instructions |
Trained via historical examples |
|
Best For |
Routine, predictable calculations |
Complex, pattern-heavy problems |
Real-Time Market Reality: The Boom of 2026
We aren’t talking about abstract computer science anymore. The corporate landscape has fully committed to this technology. Looking at financial intelligence reports for 2026 shows just how massive this shift has become.
Recent market data from Fortune Business Insights and Research Nester values the global machine learning market at roughly $62.4 billion in 2026, a sharp increase from $48.9 billion in 2025. Spending isn’t slowing down either; projections show the market soaring past $441.6 billion by 2035, driven by a steady compound annual growth rate (CAGR) of 27.7%.
Large corporate enterprises currently command nearly 60% of this market share. They are aggressively integrating these tools to automate administrative workflows, break down massive datasets, and pull out quantitative insights. Cloud deployment is leading the charge, capturing over 53% of the total market space. This means a mid-sized retail business doesn’t need to purchase massive server rooms to run high-level analytics; they can easily rent the necessary computing power right from the cloud.
|
Market Metric |
2025 Data |
2026 Data |
Projected Future |
|
Global Value |
~$48.9 Billion |
~$62.4 Billion |
~$441.6 Billion (2035) |
|
Top Segment |
Large Enterprises |
Cloud-Based Platforms |
Autonomous AI Agents |
|
Leading Region |
North America (32.5%) |
Steady US/Europe Growth |
Rapid Asia Pacific Expansion |
A Step-by-Step Breakdown: How Machine Learning Works in Practice
Building a system that accurately predicts outcomes takes real time, intense computing power, and highly structured information. Here is a clear look at the exact pipeline data scientists use to build these systems from the ground up.
- Data Collection: Everything starts here. If you want an algorithm to flag fraudulent transactions, you need a massive database of past transactions, with the fraudulent ones clearly marked.
- Data Preprocessing and Cleaning: Raw data is incredibly messy. It contains missing values, duplicate entries, and messy formatting. Data scientists spend a massive chunk of their day fixing these errors. If you feed bad data into the system, you get bad predictions out. The industry phrase is “garbage in, garbage out.”
- Algorithm Selection: Not every tool fits every job. Engineers have to decide if the goal is to predict a specific number, sort an object into a category, or find hidden groups within a customer base.
- Training the Model: This is where the actual learning happens. The algorithm looks at the data, makes a random guess, and checks its guess against the real answer. If it’s wrong, it tweaks its internal math and tries again.
- Evaluating Performance: You can’t test a system using the exact same data it just practiced on. Engineers always hold back a chunk of data, called a testing set, to see how the system performs on fresh information it has never seen before.
- Deployment and Monitoring: Once the model hits its accuracy targets, it goes live. But the job isn’t done. Engineers have to continuously track it to make sure its accuracy doesn’t drop as real-world trends shift.
|
Pipeline Phase |
Primary Objective |
Key Deliverable |
|
Collection |
Gather high-quality historical data |
Raw spreadsheets, images, or text files |
|
Preparation |
Clean up formatting errors and gaps |
An error-free, standardized dataset |
|
Training |
Run iterative guessing and checking cycles |
An optimized predictive model |
|
Evaluation |
Test performance on unseen data |
Verified accuracy metrics |
The Three Core Types of Machine Learning
Algorithms don’t all learn the same way. If you want to grasp how machine learning works across different applications, you need to understand the three primary learning styles.
Supervised Learning
This is the most common approach by far. Think of it like a student practicing math problems with a teacher looking over their shoulder. Every piece of data comes with a clear, pre-assigned label. The computer looks at an image and is explicitly told, “This is a delivery truck.” The system learns to associate the visual features of the image with that label so it can accurately identify delivery trucks in future photos.
Unsupervised Learning
Here, the computer gets a massive pile of data with zero labels or descriptions. The goal isn’t to hit a specific pre-determined answer, but to uncover hidden structures. For example, an e-commerce platform might feed an unsupervised algorithm millions of user behavior logs. The algorithm can then group those users into distinct purchasing personas that the human marketing team never even realized existed.
Reinforcement Learning
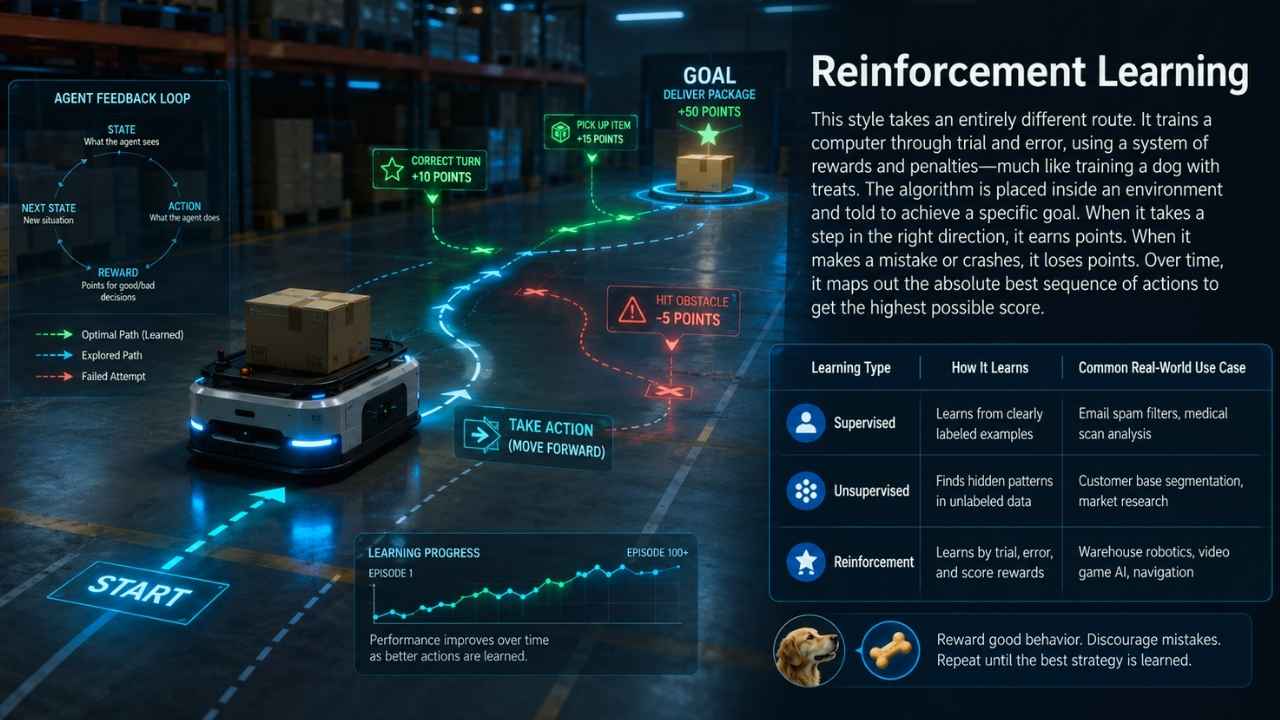
This style takes an entirely different route. It trains a computer through trial and error, using a system of rewards and penalties—much like training a dog with treats. The algorithm is placed inside an environment and told to achieve a specific goal. When it takes a step in the right direction, it earns points. When it makes a mistake or crashes, it loses points. Over time, it maps out the absolute best sequence of actions to get the highest possible score.
|
Learning Type |
How It Learns |
Common Real-World Use Case |
|
Supervised |
Learns from clearly labeled examples |
Email spam filters, medical scan analysis |
|
Unsupervised |
Finds hidden patterns in unlabeled data |
Customer base segmentation, market research |
|
Reinforcement |
Learns by trial, error, and score rewards |
Warehouse robotics, video game AI, navigation |
The Mathematical Engine: Algorithms Explained
Underneath all the tech industry hype, machine learning is really just applied statistics. The algorithm is simply the specific mathematical formula the computer uses to crunch through numbers. While there are hundreds of options, they generally fall into three main buckets.
Regression algorithms are your go-to when you need to predict a continuous numerical value. If you want to forecast next quarter’s sales revenue based on your past five years of historical performance data, you use a regression model.
Classification algorithms are designed to sort data into specific, distinct boxes. When your email provider decides whether an incoming message belongs in your main inbox or the junk folder, a classification algorithm is weighing the wording and sender history to make a clean, binary choice.
Clustering algorithms serve as the backbone for unsupervised learning. They take a chaotic mess of data points, calculate the mathematical distance between them, and bundle similar items together based on common traits.
|
Algorithm Type |
Goal |
Example Application |
|
Regression |
Predict a continuous number |
Forecasting temperature changes or stock prices |
|
Classification |
Assign a specific category label |
Identifying an email as Spam or Not Spam |
|
Clustering |
Group similar data points together |
Finding distinct customer buying profiles |
Deep Learning and Neural Networks
When you hear terms like “Deep Learning,” you are stepping into a highly specialized, incredibly powerful sub-field of AI. This is where we step away from simple mathematical trees and try to mimic the biological structure of the human brain.
A neural network is built out of artificial “neurons” stacked in interconnected layers. Data enters through the input layer, passes through several hidden middle layers where the calculations happen, and pushes out a final answer through the output layer.
Imagine you are trying to read a messy, handwritten number “8”. The first layer of neurons looks for the most basic shapes, like simple curves and straight lines. The second layer combines those raw shapes to identify closed loops. The final layer takes the presence of two stacked loops and predicts that the number is an 8.
Deep learning is simply a neural network that contains a massive number of these hidden middle layers. It’s the primary reason artificial intelligence has exploded over the last decade. The math behind neural networks has existed for a long time, but we lacked the computer chips powerful enough to run them. Today, specialized graphics processing units and massive cloud server farms make it possible to handle the billions of calculations required to train these systems.
|
Concept |
Structure |
Complexity Level |
|
Standard ML |
Flat algorithms and basic decision trees |
Moderate complexity, relatively fast to train |
|
Neural Networks |
Interconnected nodes arranged in layers |
High complexity, requires much more training data |
|
Deep Learning |
Networks with dozens of hidden layers |
Extreme complexity, requires massive computing power |
Everyday Examples: Where You See It in 2026
To understand the real scale of this technology, you only need to look at the apps running on your smartphone right now. We have moved far past theoretical computer science labs; these models run a massive portion of our daily digital lives and business operations.
Recommendation Engines: When Spotify compiles your personalized weekly playlist, it isn’t just looking at the genre of music you play. It runs an analysis on the listening habits of millions of other users across the platform. If thousands of people who share your exact taste in five specific indie rock bands also happen to stream a new pop artist, the algorithm assumes you will probably like that pop artist too.
Banking and Fraud Detection: Retail banks process millions of transactions every second. No human team could ever review them all by hand. Instead, machine learning models sit quietly in the background, learning your exact spending habits. If you typically buy coffee in London, and someone suddenly tries to buy an expensive television in Tokyo using your card credentials, the algorithm flags it as an anomaly and freezes the transaction instantly.
Natural Language Processing (NLP): Modern writing assistants, search engines, and customer support chatbots rely on algorithms trained to understand human text. They don’t just match keywords; they map out the semantic relationships between words, allowing them to understand context, sentence tone, and user intent.
|
Industry |
The ML Engine |
What It Accomplishes |
|
Media & Streaming |
Recommendation Engines |
Keeps users on the platform by predicting taste |
|
Banking & Finance |
Anomaly Detection |
Blocks stolen credit card usage instantly |
|
Healthcare |
Computer Vision |
Flags anomalies in medical X-rays and MRI scans |
|
Retail & SaaS |
Predictive Analytics |
Forecasts inventory needs and highlights churn risks |
The Hidden Challenges: Bias, Black Boxes, and Cost
We know how machine learning works well enough to build incredibly useful tools, but the technology still faces some massive hurdles. Relying entirely on historical data creates serious blind spots that tech companies are actively trying to solve.
The Problem of Data Bias: An algorithm is completely objective, but the data it learns from is created by biased humans. If a company trains a hiring model on ten years of historical employment records that heavily favored male candidates, the system will teach itself that male candidates are inherently preferable. It doesn’t have malice; it is simply replicating the patterns found in the data. If the input data is biased, the mathematical model will confidently repeat that bias.
The Black Box Problem: With a simple decision tree algorithm, engineers can look directly at the code and see exactly why a computer made a specific choice. But with massive deep learning neural networks, millions of mathematical parameters fire simultaneously. When the model outputs a final decision, even the engineers who built it can’t always trace the exact logical path it took. In fields like healthcare or criminal justice, you can’t just tell a person, “The computer said so.” You need to know why.
Compute Costs and Environmental Impacts: Training modern deep learning models requires massive server farms running specialized hardware around the clock for weeks at a time. This creates a massive financial barrier to entry for smaller startups and generates a significant carbon footprint from energy consumption.
|
The Challenge |
Why It Happens |
The Real-World Impact |
|
Algorithmic Bias |
Training data reflects historical human prejudices |
Unfair automated hiring screens or loan denials |
|
The Black Box |
Deep learning math is too complex to trace manually |
Difficulty explaining why an AI made a critical choice |
|
Compute Costs |
Massive server farms are required for model training |
High development costs and high energy usage |
The Future Landscape: Explainable AI and Autonomous Agents
As we move deeper into 2026, tech companies are shifting their focus away from simply making models bigger. Instead, they want to make them smarter, more efficient, and easier to understand. The regulatory landscape is forcing their hand.
We are seeing a major push toward “Explainable AI” (XAI). Because of upcoming regulations like the EU AI Act, companies can no longer run black box models in critical sectors. They are utilizing techniques like SHAP (Shapley Additive Explanations) and LIME (Local Interpretable Model-Agnostic Explanations) to force algorithms to show their mathematical work. For example, if an AI denies your loan application, an XAI framework will tell you exactly which factors—like debt-to-income ratio or credit history length—triggered the denial.
We are also seeing the rapid rise of Agentic AI. These autonomous AI agents are moving out of experimental phases and into corporate workflows. These tools go beyond standard chatbots. You can hand an autonomous agent a high-level goal—like “analyze our top three competitors’ pricing plans and put together a summary report”—and it will independently figure out and execute the necessary steps, pulling data, summarizing text, and formatting the final document without you having to guide it at every step.
|
Trend |
The Concept |
Business Benefit |
|
Explainable AI (XAI) |
Building models that clarify their reasoning using SHAP/LIME |
Increases trust and ensures compliance with 2026 regulations |
|
Agentic AI |
AI systems that execute multi-step goals autonomously |
Automates complex administrative workflows |
|
Edge Machine Learning |
Running predictive models locally on devices |
Lowers corporate cloud bills and protects user privacy |
Final Thoughts
The shift away from writing hard-coded software rules toward training dynamic, self-improving models has permanently altered the trajectory of global technology. Whether it’s a SaaS platform optimizing a B2B sales pipeline, a bank securing your digital assets, or a medical application spotting early warning signs in patient scans, the core mechanism remains exactly the same: gather high-quality data, pick the right mathematical engine, and let the system discover the hidden patterns.
When you strip away the science-fiction hype, understanding how machine learning works shows that it isn’t magic. It is simply applied statistics powered by massive amounts of data and modern computing chips, working around the clock to find the connections that human brains simply can’t process fast enough.
Frequently Asked Questions (FAQs) About How Machine Learning Works
What is the difference between Artificial Intelligence and Machine Learning?
Artificial Intelligence is the broad, overarching concept of machines simulating human intelligence or behavior. Machine learning is a specific subset underneath that broad AI umbrella. Think of AI as the entire automobile, and machine learning as the specific engine that allows it to move and adapt based on driving conditions.
Can an algorithm “unlearn” bad information?
Not easily. If an algorithm trains on toxic, biased, or completely incorrect data, it bakes those patterns directly into its internal mathematical weights. Engineers can’t just dive into the code and delete a single incorrect fact. They usually have to clean the dataset and retrain the entire model from scratch, or apply strict filters at the output stage to catch bad responses before a user sees them.
What is Explainable AI (XAI) and why is it trending in 2026?
Explainable AI refers to tools and techniques (like SHAP and LIME) that help humans understand exactly how a machine learning model arrived at its decision. It is highly trending right now because regulatory frameworks, like the EU AI Act, are cracking down on “black box” models in high-risk sectors like finance and healthcare, demanding transparency.
Why do large language models hallucinate facts?
Text-based models don’t actually understand the real-world meaning of the words they process. Instead, they calculate the statistical probability of what word should come next in a sentence based on their massive training data. Sometimes, the math creates a sentence structure that sounds perfectly natural and authoritative, even if the underlying statement is completely factually incorrect. They prioritize fluency over absolute truth.
How much data do you need to build a functioning model?
It depends entirely on how complex the task is. A basic supervised learning model designed to predict real estate prices might only need a few thousand spreadsheet rows to achieve solid accuracy. Conversely, a deep learning model built to navigate a self-driving car safely through city traffic requires millions of hours of high-definition video footage and petabytes of sensor logs to handle real-world chaos.


























{kind=link}